Partitioning Schemes are a way to optimize the performance of Data Flow. This setting can be accessed on the Optimize tab in the Configuration panel for the Data Flow Activity.

Microsoft recommends leaving the setting to default “Use current partitioning” in most cases. This sends an instruction to the data factory to use native partitioning schemes.
Single Partition option is used when users want to output to a single destination e.g. a single file in ADLS Gen2.
As we can see from the screenshot above, there are multiple Partition Types available after selecting the Set Partitioning radio button. Let’s have a look at these partition schemes:
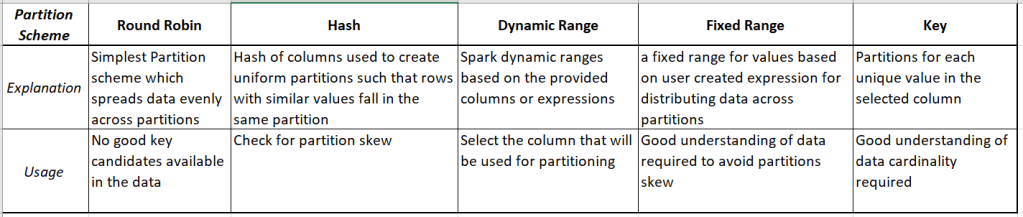
Microsoft recommends testing each of these partitioning schemes and comparing partition usage statistics using monitoring view.

One thought on “Azure Data Factory Data Flow Partitioning Schemes”