Power Query is usually associated with Microsoft’s premier BI and Data Visualization tool/service, Power BI. But there is an activity available in Azure Data Factory, called Power Query. (Currently in Preview).

Power Query activity has been designed to allow users to create data mash-ups using the powerful M language (which is the same language that is used in Power BI Power Queries).
As you may have noticed in the settings screenshot above, the Power Query Activity runs on it’s own Azure Integration Runtime. The compute type and Core Count settings are related to the Azure Integration Runtime. The settings related to Staging (Staging Liked Service and Staging Storage Folder) are required if the source that we are connecting to is SQL DW.
Please note, Power Query is also available as a separate activity/artefact by itself and can be used to transform data independently by itself. i.e., not as a part of pipeline.
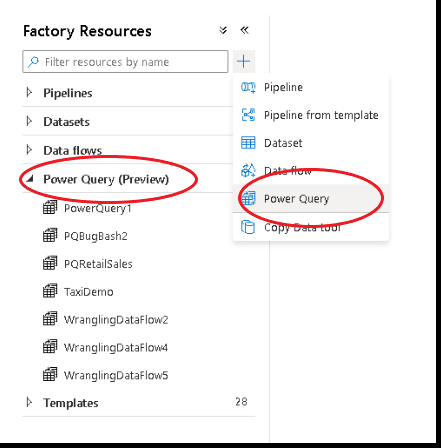
Once you create an independent Power Query activity, it can be included within a Pipeline later, if required.
Once linked to a Source dataset under the Power Query setting, the Power Query activity brings up a Power Query mash-up editor.

The Power Query mash-up editor is pretty similar to the Power Query editor available in Power BI. Users have access to in-built functions and transformations to process data without code. Also, they have access to edit the underlying M code (within the user query) directly in the Advanced Editor.
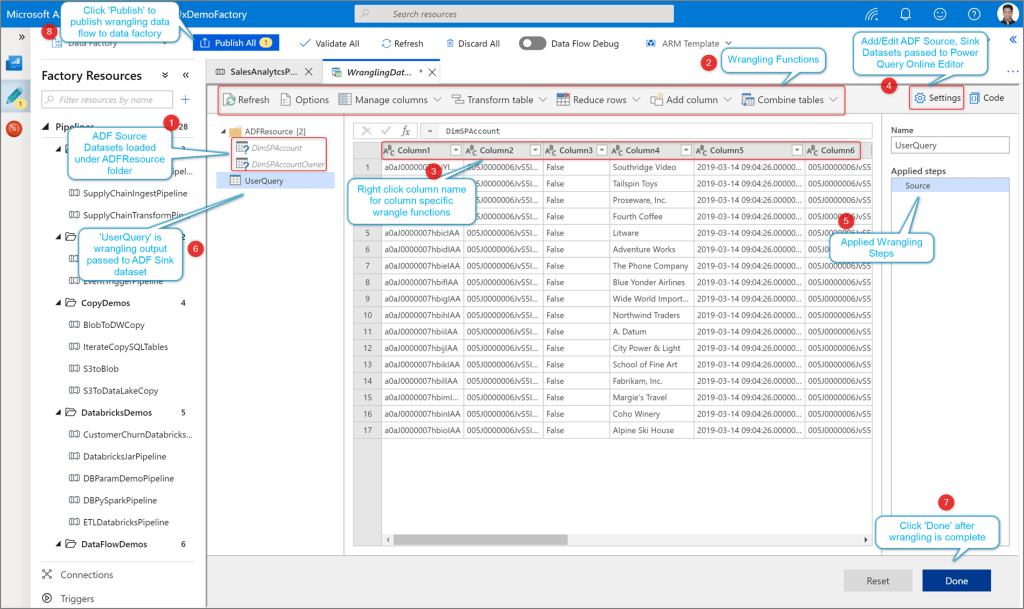
We will discuss the Power Query mashup editor in detail in a future post.
Under the hood, the Power Query activity translates the native M code to Data Flow script, in-order-to take advantage of the scalability features of Data Factory.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/control-flow-power-query-activity
