As we know, Azure Synapse Analytics has an MPP architecture, which means there are multiple nodes which can process queries in parallel. Another important concept is table distribution. There are various table distribution options suited to different use cases. We have already discussed Synapse table distributions in a previous post.
Replicated tables are replicated across every node i.e. every compute node has a copy of all the rows of the replicated table. While this sounds very convenient, there are various considerations for choosing replicated tables over others distribution types (round-robin, Hash-distributed)
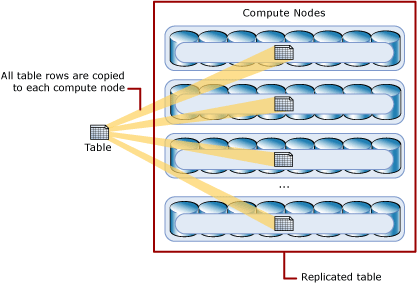
Considerations for using Replicated Tables:
- Table size < 2 GB: Microsoft recommends that the table size on disk should be less than 2GB, irrespective of the number of rows. To check the disk size of the table the DBCC PDW_SHOWSPACEUSED command can be used.
- Table used in Joins: If the table is used in Joins, especially with a Hash-distributed table. Using replicated table instead of Round-robin distributed table, would reduce the amount of data that needs to be transferred between nodes, thereby increasing query performance.
Considerations for NOT using Replicated Tables:
- Frequent DML Operations: Frequent Data Manipulation Language Operations (Insert, Update, Delete) require rebuilding of the replicated table, thereby resulting in slower performance
- Frequently scaled SQL Pool: Scaling of SQL pool would change the number of compute nodes and require rebuilding of the replicated tables.
- Few table columns accessed: If only a small subset of columns is being accessed from the table, then replicating the whole table may not result in better performance. A better option in this scenario, is to distribute the table using round-robin / hash distribution and then create an index that references the most frequently accessed columns.
Microsoft also recommends converting existing round-robin or Hash distributed tables to replicated tables if they satisfy the criteria listed above.
