Azure Synapse Analytics is designed to process huge amounts of data. Sometimes, tables in Synapse Analytics can have hundreds of millions of rows. Even with these huge amounts of data loads, Syanpse Analytics processes complex queries and returns the query results within seconds. This is possible, because Synapse SQL runs on a Massively Parallel Processing (MPP) architecture where the processing of data is distributed across multiple nodes.
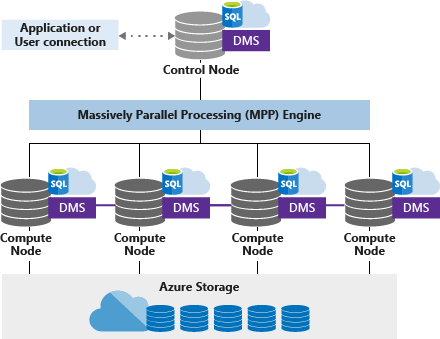
Applications connect to a control node. As the name suggests, a control node acts as a point of entry to the Synapse Analytics MPP engine. After receiving the Synapse SQL query, the control node then breaks it down into MPP optimized format. The individual operations are then forwarded to the compute nodes. These compute nodes can perform the operations in parallel thereby resulting in much better query performance.
To implement parallel processing of Synapse SQL, Data Movement Service (DMS), an internal service manages the data movement across compute nodes as and when required.
The term for provisioned resources in Synapse Analytics is Synapse SQL Pool. Synapse SQL pools can be scaled by Data Warehouse Units (DWUs). A DWU is an abstraction of compute power i.e. CPU, memory and IO. The important thing to note is that the storage is not a part of DWU. This means that the storage can be scaled independently.
This approach of having compute and storage scale independent of each other comes with various benefits to the users. E.g. it is possible to pause the compute capacity without removing the data, so the users have to pay only for the storage and not the compute resources.

5 thoughts on “Azure Synapse Analytics Architecture”