We learnt about Azure Synapse Analytics architecture in the previous post. Another important concept to understand in the Synapse Analytics parallel processing query execution is distribution. A distribution is the basic unit of storage, in the context of parallel query processing.
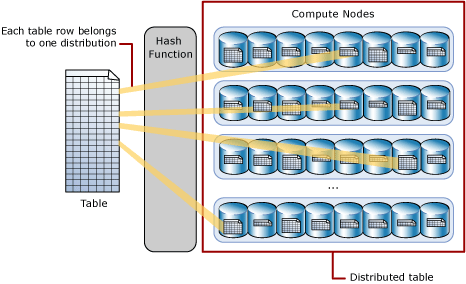
Internally, Synapse SQL breaks down the work into 60 smaller parts. Each of these 60 smaller queries runs in parallel on one distribution. These distributions are managed by compute nodes. Depending on the compute resources configured, one compute node can manage one or more distribution. So, the configuration can range from a single compute node for all distributions to one compute node per distribution. The process of breaking down table data into smaller distributions in called sharding.
A table distribution can be implemented in various ways:
- Hash-distributed Tables: This distribution is generated by a deterministic hash-function. Values from the identified distribution column in the table are used to assign each row to a distribution. Important thing to note here is that the number of rows in each distribution varies. Hash distributions are ideal for large tables that have lots of joins and aggregations e.g. Fact Tables in a Data Warehouse.
- Round-robin distributed Tables: This is the simplest form of table distribution. It is ideal for staging tables and delivers fast performance while loading data. The first distribution is chosen at random and data is distributed sequentially and evenly across the distributions. This distribution is not optimized for query performance or joins but provides fast loading speeds. It is recommended to use round-robin distribution when the table size in 2 GB or less.
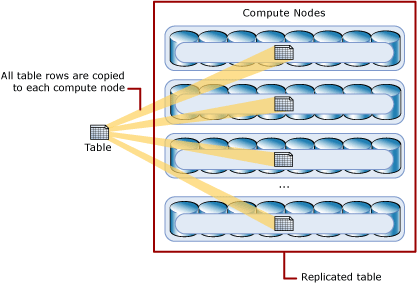
- Replicated Tables: As the name suggests, all the rows are cached to each compute node, making this ideal for tables with small size. Since, the whole table is available at each node, there is no need to transfer data between nodes, making the query performance extremely fast. Replicated Tables require more storage space and are therefore not recommended for large tables.

3 thoughts on “Azure Synapse Analytics Table Distributions”