In the previous post, we discussed Lakehouse, had a brief look at the DW architecture and how it has evolved with time. In this post, lets have a look at how we can use Microsoft Azure services and features to implement a Lakehouse.
In case you are not familiar with DW architecture evolution, a Lakehouse is the latest DW architecture which has evolved from the Data Lake architecture. It makes logical sense for the Lakehouse implementation to be based on top of a Data Lake, such as, ADLS.
Before we move ahead, lets understand, what is Delta Lake architecture?
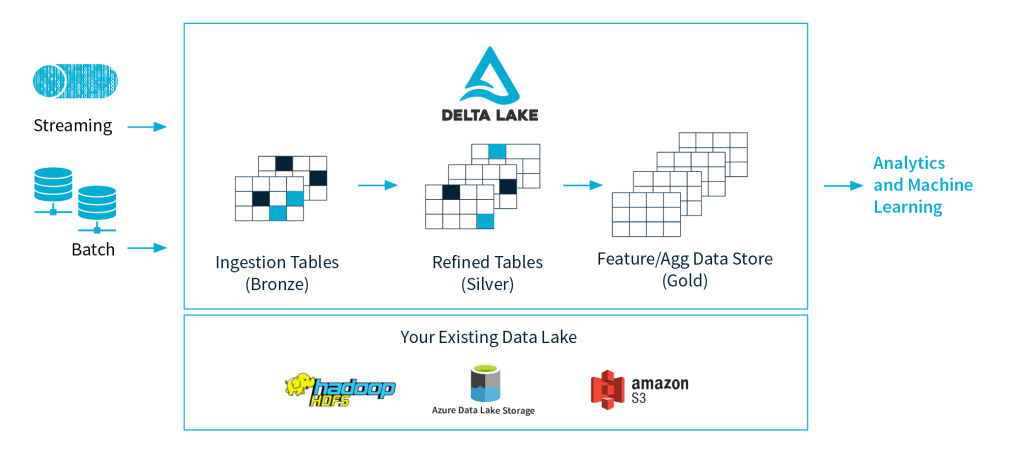
To put it simply, Delta Lake is an open-source architecture for building a Lakehouse, by creating a structured layer for all types of data (including unstructured data) stored in a Data Lake. This structured layer enables some features which are similar to the features available in relational databases, along with other features which are beyond the capabilities of traditional relational databases. Let’s have a look at the main features Delta Lake offers:
- ACID Transactions: ACID transactions form the base of a trustworthy database. By utilizing the serializable isolation levels that Spark provides, Delta Lake ensures that the data exposed to the users is always consistent and reliable.
- Scalable Metadata Handling: By utilizing the Distributed Data Processing Engine within Spark, Delta Lake can handle petabyte-scale tables with billions of underlying files, with ease.
- Handling Batch Loads and Streaming Data: Delta Lake tables can be used as both, as traditional batch load tables, as well as a source or sink for streaming data. This is possible due to the logical table structure that is created by Delta Lake architecture on top of the underlying Data Lake storage.
- Schema validation and enforcement: Just as we use database constraints to validate and enforce the data structure for a table column in a traditional SQL database, with Delta Lake, we can enforce schema rules to prevent bad records from being ingested.
- Data versioning and time travel: Delta Lake supports data versioning i.e., it is possible to access the data stored in a Delta Lake table at particular point in time and perform historical audits.
- Upserts and deletes: This feature is very useful for DW dimension loads. Delta Lake supports Merge statement which can be used to implement slowly changing dimensions (SCD) loads.
Reference: https://docs.microsoft.com/en-us/azure/databricks/delta/delta-intro
